OpenAIがリリースした高精度な音声認識モデル”Whisper”を使って、オンライン会議の音声を書き起こししてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データアナリティクス事業本部 機械学習チームの中村です。
2022/09/22の夕方ごろ、OpenAIが音声認識ですごいものを出したらしいというニュースが社内のSlackをにぎわせていました。
個人的には、いくら認識が凄いって言っても、実際日本語は微妙なんじゃないかな…?と思っていたのですが…
ですが…
…
…
…
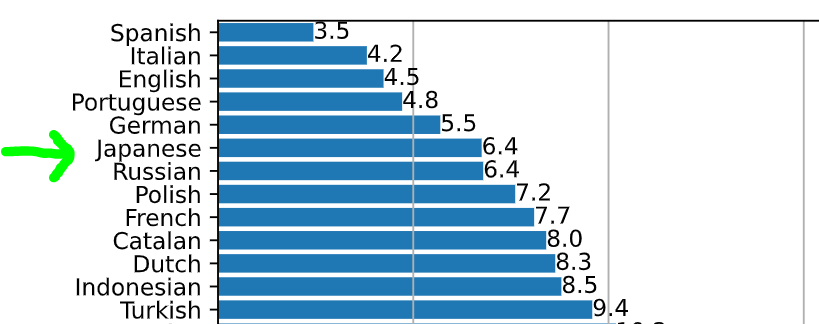
おお!?(上記はGitHubにあるWER: Word Error Rateのグラフです)
これは!?
これは結構良さげな数値を出している!?(たぶん)
ってことで元音声屋さんとしては、これは試すしかない!ということで動かしてみました!(投稿は翌日になってしまいましたが…)
なお、本記事では論文内容の詳細などには触れませんのでご了承ください。(後日できたらがんばります)
いますぐ使いたい人向け
今すぐ使いたい方は、Hugging Faceでブラウザから書き起こしを試すことができるようですので、ご自身のヘッドセット等でお試しください。
Whisperの概要
論文の内容には触れませんと言ったものの、概要には少しだけ触れたいと思います。
Whisperは汎用的な音声認識モデルであり、多様な音声の大規模データセット(680,000時間)で学習されており、 音声認識に加えて、音声翻訳、言語識別、多言語音声認識にも対応したマルチタスクモデルです。
論文の冒頭を読んだところ、ポイントとしては、近年の音声認識の大規模化で主流なself-supervisionやself-trainingテクニックを用いずに、 弱教師有(weakly supervised)の音声認識を680,000時間のデータに拡張した点のようです。論文内ではこれをWhisper2と呼んでいます。
OpenAIの公式ページは以下で、そこから論文やGitHubへのリンクも記載されています。
モデルは以下の5種類準備されています。

本記事では、このうちbaseとlargeのモデルを使って検証をしていきます。
やってみた
実行環境
今回はGoogle Colaboratory環境で実行しました。
ハードウェアなどの主な情報は以下の通りです。
- GPU: Tesla P100 (GPUメモリ16GB搭載)
- CUDA: 11.1
- メモリ: 26GB(ハイメモリタイプ)
主なライブラリのバージョンは以下となります。
- transformers: 4.22.1
- whisper: 1.0
インストール
pipでgitからインストールできます。とても簡単ですね。
!pip install git+https://github.com/openai/whisper.git
ffmpegも必要ですが、Colabにはあらかじめインストール済みのため特に設定は不要のようです。
インポート
python上で動作させてみます。準備としてはwhisperをインポートするのみです。
import whisper
データの準備
そしてデータを準備していきます。
今回は社内の勉強会で私がメインで発表した会があったので、その会議の録画データを使います。
録画はGoogle Meetの録画機能を使ったものです。
全体のデータは45分と長いので、Colab上でffmpegを使い30秒分を切り出します。(ついでに今回は音声ファイルに変換してますが、Whisperは動画ファイルのままでも処理できるらしいです、便利…)
!ffmpeg -i "{元の動画データ}" -ss 71 -to 101 -ac 1 "output.wav"
出力チャンネルは指定しないとステレオになってしまったため、モノラルを指定(-ac 1)しておきました。
確認のため音声データをスペクトログラムで可視化してみましょう。
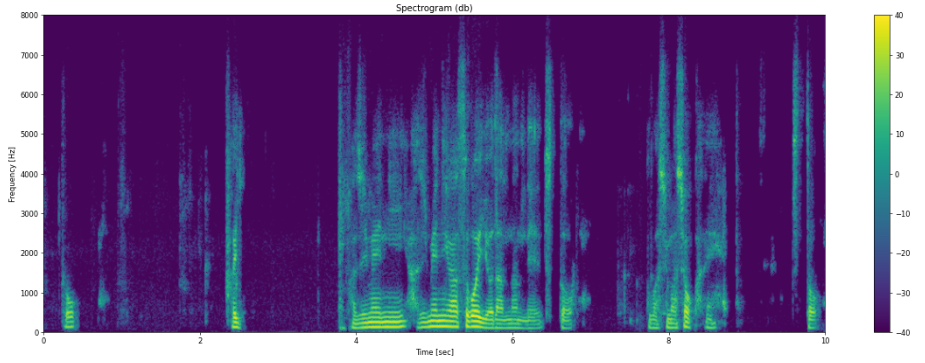
サンプリングレートはフォーマットとしては48kHzとなっていたので24kHzまで表現できるはずですが、今回は8kHzまでしか成分が見当たらなかったのでその部分を拡大表示しています。
また時間幅も先頭の10秒のみ表示しています。
スペクトログラムに馴染みのない方は、とりあえず横方向の縞の成分が音声だという風に認識頂ければOKです。
可視化用のプログラムは以下を参照ください。
import numpy as np
import librosa
from matplotlib import pyplot as plt
# スペクトログラム表示用関数
# 分かりやすさのため、表示帯域は1/6に、時間は1/3にしている
# また、比較できるようパワースペクトルのダイナミックレンジは-40~40に固定
def plot_spectrogram(wav_file, n_fft=2048, win_length=None, hop_length=512, window_fn='hann'):
waveform, sample_rate = librosa.load(wav_file, sr=None, mono=False)
print(f"sample_rate: {sample_rate}")
if len(waveform.shape) == 2:
print("stereo")
spec = np.abs(librosa.stft(y=waveform[0],
n_fft=n_fft, hop_length=hop_length, win_length=win_length, window=window_fn))**2
else:
print("mono")
spec = np.abs(librosa.stft(y=waveform,
n_fft=n_fft, hop_length=hop_length, win_length=win_length, window=window_fn))**2
fig, axs = plt.subplots(1, 1, figsize=(24, 8), dpi=60)
axs.set_title("Spectrogram (db)")
axs.set_ylabel("Frequency [Hz]")
axs.set_xlabel("Time [sec]")
pow = librosa.power_to_db(spec)
im = axs.imshow(pow[:n_fft//6,:pow.shape[1]//4],
origin="lower", aspect="auto", extent=(0, 30//4, 0, sample_rate//6), vmin=-40, vmax=40)
fig.colorbar(im, ax=axs)
plt.show(block=False)
書き起こししてみた
それでは音声に対して、baseモデルを使って書き起こししてみます。
model = whisper.load_model("base")
result = model.transcribe("output.wav")
print(result["text"])
出力は以下となりました。
Detected language: japanese とはい初めに初めにはすごい予断なんでちょっとおはしましょうかね ちょっといろいろしてますけど16時間物を食べないっていうのを最近 やってますっていう話です興味あったら見たいってくださいはいでち ょっとおくじの方は前回から被害ってるので前回のおさらいの方
認識結果は勉強会ということで多少口語となっているため、苦しい部分もあるものの、おおむね正解していそうです。 (何をしゃべってるかというと、完全に冒頭の余談で、オートファジーについてしゃべっています。)
多少間違っている部分としては以下です。
- おはしましょうかね → はしょりましょうかね
- 見たいってください → 見といてください
- おくじ → 目次
- 被害ってる → 日がたっている
それに加え……お気づきでしょうか……
Detected language: japanese
そうです!言語も自動で判定!?しているようですね!!(さすがマルチタスク対応ですね)
また結果のresultにはdict形式でさまざまな結果が入っています。
例えば、セグメント単位で情報が記載されているので、これを見ていきたいと思います。
import pandas as pd pd.DataFrame(result["segments"])[["id", "start", "end", "text"]]
結果は以下のようになっています。
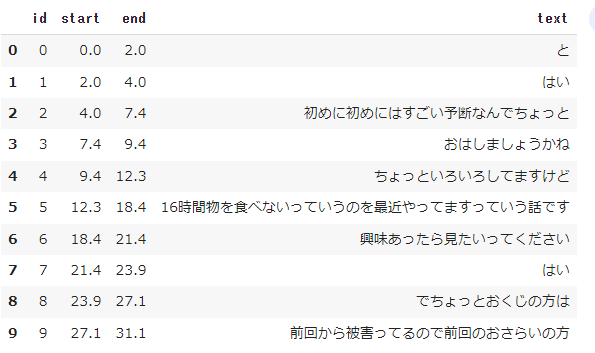
start, endという時間情報もあるので、字幕情報を付けることも可能そうですね。
あとはノイズにどの程度強いのでしょうか…ここら辺も気になるためちょっと見ていきたいと思います。
ノイズデータを準備する
適当にiphoneで録音したデータを使用します。アプリは以下を使用しました
ノイズ音は、部屋の中で音を立てながら毎日がんばってくれているサーキュレーターに、スマホを近づけて録音しました。

収録したデータを、ミックスするために30秒に切り出しします。
!ffmpeg -i "{ノイズデータの元ファイル}" -ss 0 -to 30 "noise.wav"
こちらも音声データと同様に可視化してみます。
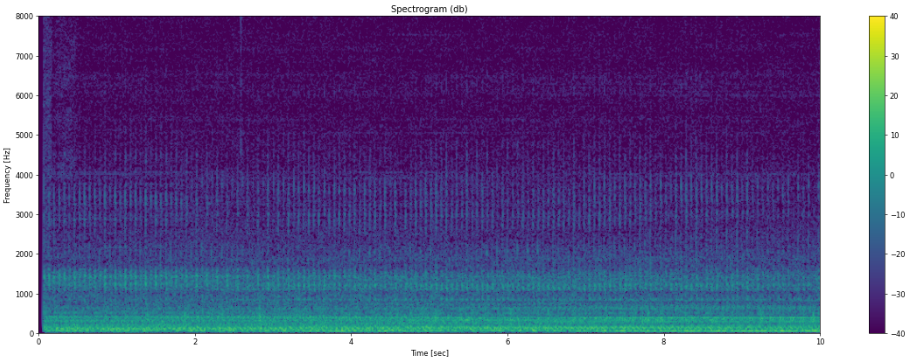
まあまあの大きさですので雑音試験には適しているかなと考えました。
こちらをミックスします。
!ffmpeg -i "output.wav" -i "noise.wav" -filter_complex "amerge=inputs=2" -ac 1 "mix.wav"
ミックス結果を可視化してみましょう。
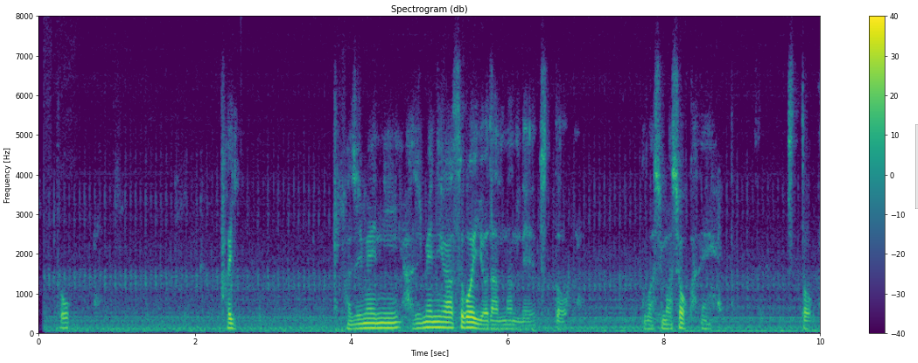
良い感じにノイズが加算されていることが分かります。
ノイズデータでの実験
ノイズをミックスしたデータで書きおこしを試してみましょう。
model = whisper.load_model("base")
result = model.transcribe("mix.wav")
print(result["text"])
結果は以下でした。
Detected language: japanese はい初めに初めにはすごい予断なんでちょっとおはしましょうかね ちょっといろいろしてますけどという6時間物を食べないっていうのを 最近やってますっていう話です興味あったら見たいってください はいでちょっとお口の方は前回から控えてるので前回のおさらいの方
間違えている部分は、ノイズミックス前と同じ場所かなというところで、そこまで劣化しない印象を受けました。
largeモデルも試してみよう
一番大きいlargeモデルも試してみます。
まずはノイズをミックスする前のものです。
model = whisper.load_model("large")
result = model.transcribe("output.wav")
print(result["text"])
出力です。
Detected language: japanese 初めにがすごい余談なので 少し飛ばしましょうかねいろいろしてますけど 16時間物を食べないっていうのを最近やってますっていう話です 興味あったら見ておいてくださいちょっと木地の方は 前回から日が空いてるので 前回のおさらいの方
...これは!!ほぼ合っています!!
しかもbaseと異なり、分の切れ目もきちんとスペースで区切られていました!!
30秒データに対して、35秒ですのでリアルタイム処理はちょっと厳しくなっていますが、GPU選定次第では超えられる可能性を感じさせます。
ノイズミックスもやってみます。
model = whisper.load_model("large")
result = model.transcribe("mix.wav")
print(result["text"])
出力です。
Detected language: japanese 初めにがすごい余談なんで ちょっと 延ばしましょうかね ちょっといろいろしてますけど 16時間物を食べないっていうのを最近 やってますっていう話です 興味あったら見ていてください ちょっと北地の方は 前回から日が空いてるので 前回のおさらいの方
結果としては、若干精度低下するものの、主観としてはそこまで悪くなっていなさそうです。
CPUでも動くか?
(※2022-09-29更新:計測手法に修正すべき点があったので記載を直しています)
実際、無償版のColabなどの場合、GPUを使えるかどうか、CPUだけでできないかな、という声もあるかと思いますので試してみました。
結論から申し上げますと、CPU(標準メモリ)でもbaseモデルであればギリギリでリアルタイム処理が可能そうです。
またGPUを使用すれば、largeモデルであってもリアルタイムで処理が可能です。
比較のために下表に30秒のデータを処理した時の処理時間計測結果を記載します。
| ランタイムタイプ | model | 処理時間 |
|---|---|---|
| GPU(Tesla P100) / ハイメモリ(26GB) | base | 約1.2秒 |
| GPU(Tesla P100) / 標準メモリ(13GB) | base | 約1.1秒 |
| CPU / ハイメモリ(26GB) | base | 約14.8秒 |
| CPU / 標準メモリ(13GB) | base | 約28.0秒 |
| GPU(Tesla P100) / ハイメモリ(26GB) | large | 約8.4秒 |
| GPU(Tesla P100) / 標準メモリ(13GB) | large | 約8.5秒 |
| CPU / ハイメモリ(26GB) | large | 約6分 |
| CPU / 標準メモリ(13GB) | large | 約11分 |
CPUでも動かせる版があるというのは、AWSなどの上でアーキテクチャを検討する際も選択肢が増えそうで良いですね。
ノイズをマシマシにしてみる
最後にもう少しだけノイズデータを増やしてみましょう。
ノイズ2倍
ffmpegで以下のようにすれば、重みを付けてミックスが可能です。下記はノイズのボリュームが2倍になっています。
!ffmpeg \
-i "output.wav" \
-i "noise.wav" \
-filter_complex \
"[0:a]volume=1.0,channelsplit=channel_layout=mono[a1];\
[1:a]volume=2.0,channelsplit=channel_layout=mono[a2];\
[a1][a2]amerge=inputs=2" \
-ac 1 \
"mix-noise-weight2.wav"
可視化すると、先ほどよりノイズが濃くなっていることが分かります。
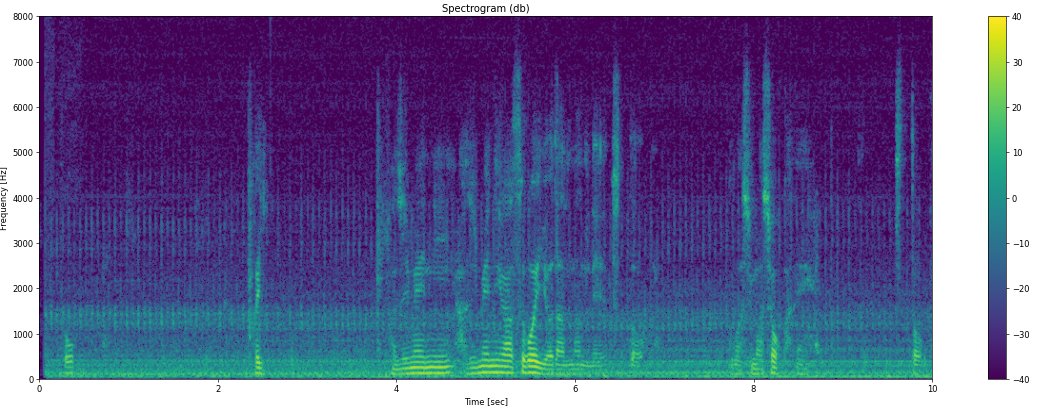
認識させた結果は以下となりました。(コードは同じなので割愛します)
- baseモデル
おっはい初めに初めにはすごいよだなんでちょっとおはしましょうかね ちょっといろいろしてますけどで6時間も物を食べないっていうのを最近 やってますっていう話です興味あったら見たいってくださいはいでちょ っとおくじの方は前回から被害ってるので前回のおさらいの方
- largeモデル
はい 初めにがすごい余談なんでちょっと延ばしましょうかね ちょっと 色々してますけど16時間ものを食べないっていうのを 最近やってますっ ていう話です興味あったら見ておいてくださいはいちょっと木地の方は 前回から日が空いてるので前回のおさらいの方
baseは若干の性能低下が見られますね。largeは高い精度を維持していそうです。
ノイズ8倍!!
もう一声、ノイズを多くしてみます。
!ffmpeg \
-i "output.wav" \
-i "noise.wav" \
-filter_complex \
"[0:a]volume=1.0,channelsplit=channel_layout=mono[a1];\
[1:a]volume=8.0,channelsplit=channel_layout=mono[a2];\
[a1][a2]amerge=inputs=2" \
-ac 1 \
"mix-noise-weight8.wav"
可視化すると、ほぼ音声の横縞が埋もれていることが分かります。
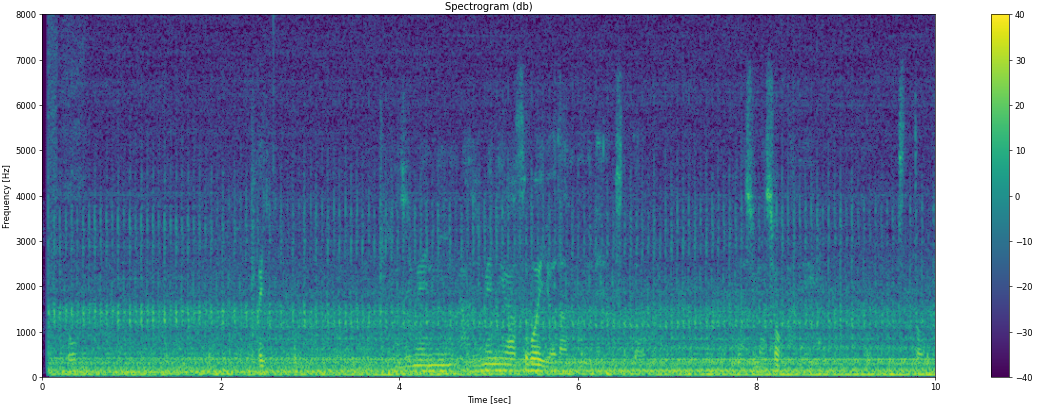
- baseモデル
こう、はい、初めには、初めにはすごいようだったので、ちょっと、おしましょ うかね、ちょっといろいろしてますけど、というお越しがむものを食べないって いうのを、大事になってますっていう話です。今日もやったら、みたいな感じか なと思います。はい、で、ちょっとお口の方は、前回からしがえてるので、前回 からさらに行こう。
- largeモデル
はい、はじめに、はじめにがすごい余談なので、ちょっと、どうしましょうかね。 ちょっと色々してますけども、16時間ものを食べないっていうのを最近やってます っていう話です。興味あったら見ておいてください。はい、ちょっと木地の方は、 前回から日が空いてるので前回のサーレイの方を
base側はかなり影響が出ていることが分かります。加えて実行のたびに結果にばらつきがあるので、確率的な部分が出てくるようです。
large側も影響でていますが、まだまだ高い精度を維持していそうです。
ノイズに対する結果まとめ
記事が長くなり分かりにくくなったので、ノイズの結果をまとめておきます。
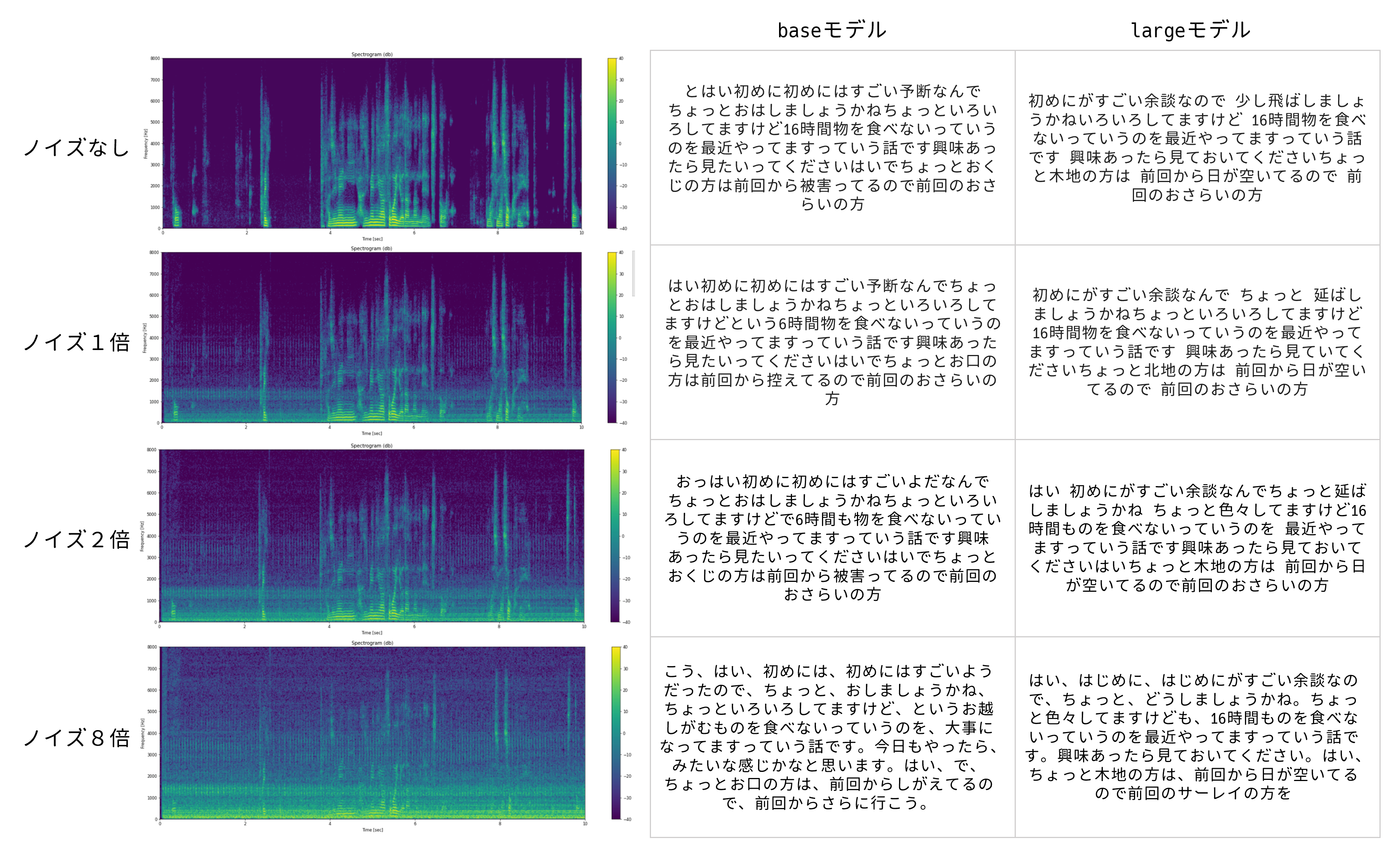
右上のノイズなし、largeモデルが最も条件が良いのでリファレンスと思ってご覧ください。
まとめ
いかがでしたでしょうか?
他にも様々なデータでの検証や、機能を試してみたかったのですが今回はここまでとさせてください。
主観ではかなり高精度が期待できそうだなという印象で、音声認識が様々なところに取り入れられそうな可能性を感じました。実際にはユースケースによって求められる精度がかわってくるため、条件に合わせた検証は必要だと思います。 今後も追加の検証や機能の確認、または論文の内容などが整理できたら、記事にしていければと思います。
本記事がwhisperを試してみようと思われる方の参考になれば幸いです。
参考ページ
- スペクトログラム可視化関連
- ffmpegの使い方関連







